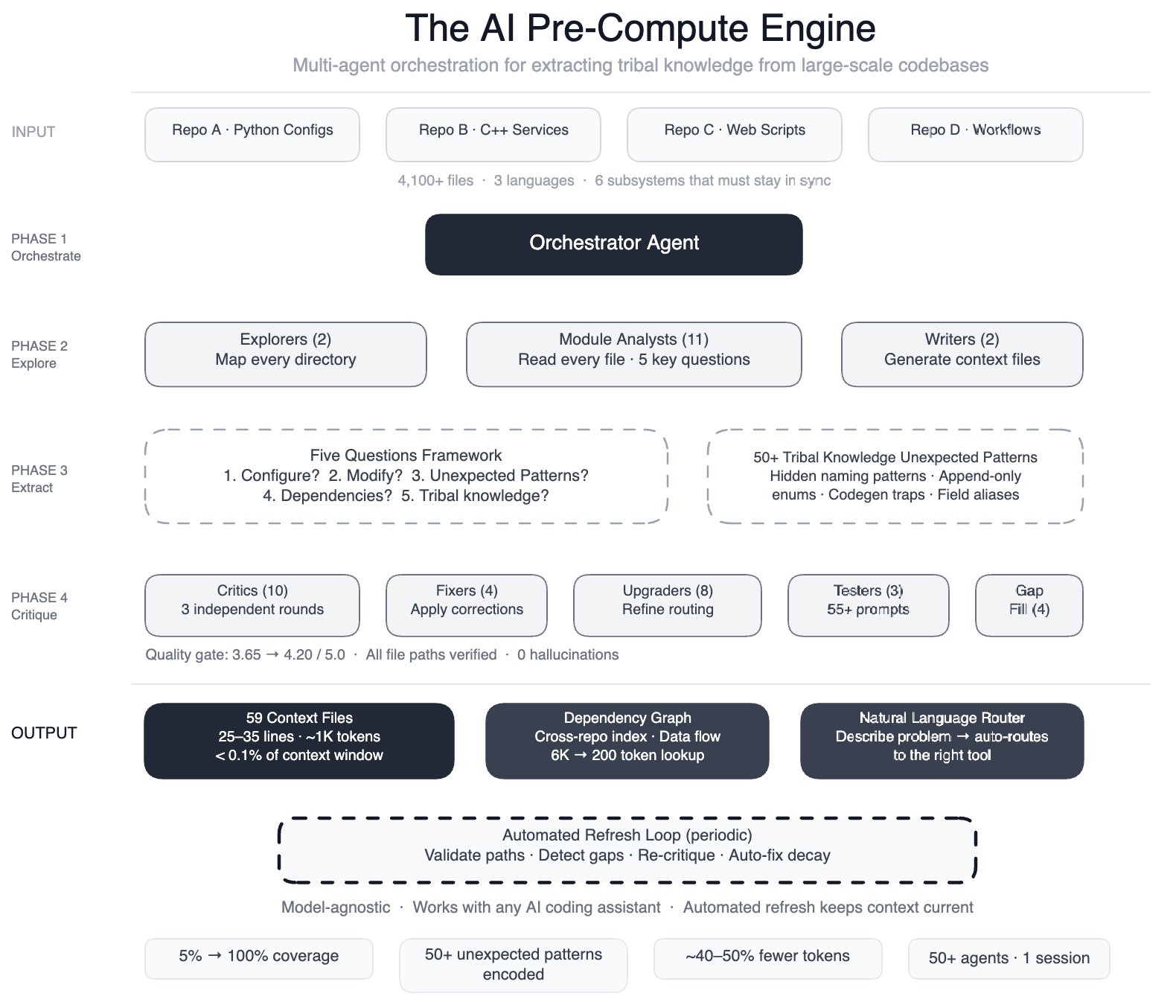
<p><span style="font-weight: 400;">AI coding assistants hold significant promise, but their effectiveness is largely determined by their comprehension of the existing codebase. When we tasked AI agents with navigating one of Meta’s extensive data processing pipelines – incorporating four repositories, three programming languages, and over 4,100 files – it quickly became evident that </span><span style="font-weight: 400;">the agents were unable to make valuable modifications in a timely manner.</span><span style="font-weight: 400;"> </span></p>To address this issue, we developed a pre-compute engine comprising over 50 specialized AI agents. These agents meticulously analyzed every file, generating 59 concise context files that captured essential knowledge previously held exclusively by our engineers. As a result, our AI agents now have structured navigation for all our code modules (an increase from 5%, covering every one of the 4,100+ files across three repositories). We have also cataloged over 50 “non-obvious patterns” – design choices and connections not immediately evident from the code itself. Initial assessments indicate a reduction of 40% in AI agent tool calls per task. It’s worth noting that the knowledge layer is designed to be model-agnostic, allowing it to function with most leading AI models.
Furthermore, the system is self-sustaining. Every few weeks, automated processes check file paths, identify coverage gaps, rerun quality assessments, and resolve outdated references. The AI serves as the driving force behind this infrastructure rather than merely consuming it.
The Challenge: AI Tools Lacking a Navigation System
Our pipeline utilizes a config-as-code approach: Python configurations, C++ services, and Hack automation scripts work in unison across various repositories. For instance, a single data field onboarding interacts with configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts—six subsystems that need to be continuously aligned.
While we had developed AI-powered systems for operational tasks, such as scanning dashboards and pattern-matching with historical incidents, attempting to extend this to development tasks proved ineffective. The AI lacked a comprehensive map. It didn’t recognize that two configuration modes employ different field names for the same function (swapping them results in silent errors) or that numerous “deprecated” enum values must remain intact due to serialization compatibility.
Without this contextual understanding, agents engaged in guesswork, often resulting in code that compiled but was subtly incorrect.
Our Solution: Educating Agents Before They Traverse
We employed a large-context-window model alongside task orchestration to organize the work into distinct phases:
- Two explorer agents mapped the entire codebase,
- 11 module analysts scrutinized each file and addressed five critical questions,
- Two writers crafted context files, and
- Over 10 rounds of critiques were conducted for independent quality assessment,
- Four fixers implemented necessary corrections,
- Eight upgraders refined the routing layer,
- Three prompt testers validated over 55 queries for five user personas,
- Four gap-fillers addressed remaining directories, and
- Three final critics executed integration tests — a total of over 50 specialized tasks orchestrated in a single session.
The five questions each analyst addressed for their respective module included:
- What functionality does this module configure?
- What are the typical modification patterns?
- What non-obvious patterns can cause build failures?
- What dependencies exist across modules?
- What hidden knowledge resides in code comments?
The insights gained from the fifth question were particularly enlightening. We uncovered over 50 non-obvious patterns, such as intermediate naming conventions, where one stage of the pipeline generates a temporary name that is then renamed in a downstream stage (referencing the incorrect name results in silent failures), or append-only identifier rules where the removal of a deprecated value disrupts backward compatibility. This knowledge was previously undocumented.
Our Creation: A Navigation Tool, Not Just Documentation
Each context file embodies our “compass, not encyclopedia” principle—comprising 25 to 35 lines (approximately 1,000 tokens) split into four sections:
- Quick Commands (easy copy-paste operations).
- Key Files (the 3 to 5 essential files).
- Non-Obvious patterns.
- See Also (cross-references).
Every line is purposeful; together, all 59 files occupy less than 0.1% of a typical modern model’s context window.
Additionally, we designed an orchestration layer to direct engineers to the appropriate tools based on natural language input. For instance, typing “Is the pipeline functioning properly?” prompts the system to review dashboards and match against 85+ historical incident patterns. If an engineer types, “Add a new data field,” the system generates the configuration and validates it in multiple phases. Engineers articulate their issues, and the system handles the rest.
The system refreshes automatically every few weeks, checking file paths, identifying gaps in coverage, rerunning evaluations, and correcting any issues. Context that is out-of-date can be more detrimental than having no context at all.
In addition to the individual context files, we have created a cross-repo dependency index and data flow diagrams that illustrate how changes ripple through repositories. This transforms the question “What depends on X?” from an exhaustive multi-file exploration (approximately 6,000 tokens) into a streamlined graph lookup (around 200 tokens) within a config-as-code setting, where a single field modification can affect six subsystems.
Outcomes
| Metric | Before | After |
| AI context coverage | ~5% (5 files) | 100% (59 files) |
| Codebase files with AI navigation | ~50 | 4,100+ |
| Tribal knowledge documented | 0 | 50+ non-obvious patterns |
| Tested prompts (core pass rate) | 0 | 55+ (100%) |
In preliminary trials across six tasks within our pipeline, agents utilizing pre-computed context achieved a reduction of approximately 40% in tool calls and tokens used per task. Workflow guidance that once necessitated about two days of research and discussion with engineers can now be completed in roughly 30 minutes.
Quality was paramount; three rounds of independent critiques improved scores from 3.65 to 4.20 out of 5.0, with all referenced file paths verified without any errors.
Reevaluating Conventional Wisdom on AI Context Files
Recent academic studies have suggested that AI-generated context files can actually hinder agent success rates in established open-source Python repositories. While this finding merits thoughtful consideration, it is limited in scope: it was assessed using codebases like Django and matplotlib, which models are already familiar with from pretraining. In such instances, context files may turn out to be redundant.
Conversely, our codebase represents a unique case: proprietary config-as-code containing tribal knowledge that isn’t found in any model’s training data. We made three design choices to mitigate the issues identified in previous research: the files are concise (~1,000 tokens, rather than being exhaustive), opt-in (loaded when needed rather than always being active), and subject to quality assessments (multiple rounds of critique and automatic self-refresh).
The most compelling argument is that without context, agents expend 15–25 tool calls in a futile search process, miss naming conventions, and produce code that is subtly flawed. The consequences of failing to provide context are significantly higher.
How to Implement This in Your Own Codebase
This strategy is not exclusively tailored to our pipeline. Any team managing a large, proprietary codebase can reap similar benefits:
- Identify Tribal Knowledge Gaps. Where do AI agents face the most challenges? Common answers lie in domain-specific conventions and cross-module dependencies that lack documentation.
- Implement the “Five Questions” Framework. Instruct agents (or engineers) to answer: What is its functionality, how can it be modified, what causes failures, what relies on it, and what remains undocumented?
- Adhere to the “Compass, Not Encyclopedia” Principle. Ensure context files are limited to 25–35 lines. Actionable guidance is preferable to exhaustive documentation.
- Establish Quality Controls. Utilize independent critiques to evaluate and enhance generated context. Avoid relying on unverified AI output.
- Automate Freshness. Outdated context can be more harmful than lacking context altogether. Implement periodic validations and self-repair mechanisms.
Future Directions
We aim to broaden context coverage for additional pipelines within Meta’s data infrastructure, while also examining ways to more tightly integrate context files with code generation workflows. Additionally, we are exploring whether the automated refresh process can identify not only outdated context but also emerging patterns and new tribal knowledge arising from recent code reviews and commits.
This approach has transformed undocumented tribal knowledge into structured, AI-compatible context—a resource that grows richer with each subsequent task.
</div><script type="text/javascript" id="gdprconsent-js-after">/ <![CDATA[ /
if (window.gdprSafeTrack) {
window.gdprSafeTrack(‘https://www.googletagmanager.com/gtag/js?id=391063774‘);
window.gdprSafeTrack(function() {
var google_analytics_g4 = decodeURIComponent( ‘391063774’ );
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag(‘js’, new Date());
gtag(‘config’, google_analytics_g4);
});
}
if (window.gdprSafeTrack) {
window.gdprSafeTrack(function() {
var google_tag_manager = decodeURIComponent( ‘GTM-KZRLGZ8’ );
(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({‘gtm.start’:
new Date().getTime(),event:’gtm.js’});var f=d.getElementsByTagName(s)[0],
j=d.createElement(s),dl=l!=’dataLayer’?’&l=”+l:”‘;j.async=true;j.src=”https://www.googletagmanager.com/gtm.js?id=”+i+dl;f.parentNode.insertBefore(j,f);
})(window,document,’script’,’dataLayer’, google_tag_manager);
});
}
if (window.gdprSafeTrack) {
window.gdprSafeTrack(function() {
var facebook_pixel = decodeURIComponent( ‘660742068067366’ );
!function(f,b,e,v,n,t,s)
{if(f.fbq)return;n=f.fbq=function(){n.callMethod?
n.callMethod.apply(n,arguments):n.queue.push(arguments)};
if(!f._fbq)f._fbq=n;n.push=n;n.loaded=!0;n.version=’2.0′;
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(t,s)}(window, document,’script’,
‘https://connect.facebook.net/en_US/fbevents.js‘);
fbq(‘init’, facebook_pixel);
fbq(‘track’, ‘PageView’);
});
}
//# sourceURL=gdprconsent-js-after
/ ]]> /