
The issue of fabricated citations in high-profile AI conferences is increasingly alarming, as accepted papers often include fictitious references that do not correspond to any actual publication. In response to this concern, a new tool called CiteAudit has been developed to systematically address the problem for the first time.
These fictitious references can appear highly credible due to the ability of language models to convincingly generate titles, author names, and conference details. Additionally, as the volume of citations has surged, manually verifying references has become impractical for reviewers and co-authors.
When a paper relies on a non-existent source to support a claim, the entire argument becomes flawed. This not only inhibits reviewers from evaluating the reasoning but also places co-authors’ reputations at risk and undermines reproducibility. The researchers assert that these instances compromise “multiple layers of the research process.”

Current citation verification tools have significant limitations. The researchers found that these tools often fail when confronted with the diverse formatting of real-world citation data, and many are proprietary, which hinders fair comparison and independent verification.
Nearly 10,000 citations put detection tools to the test
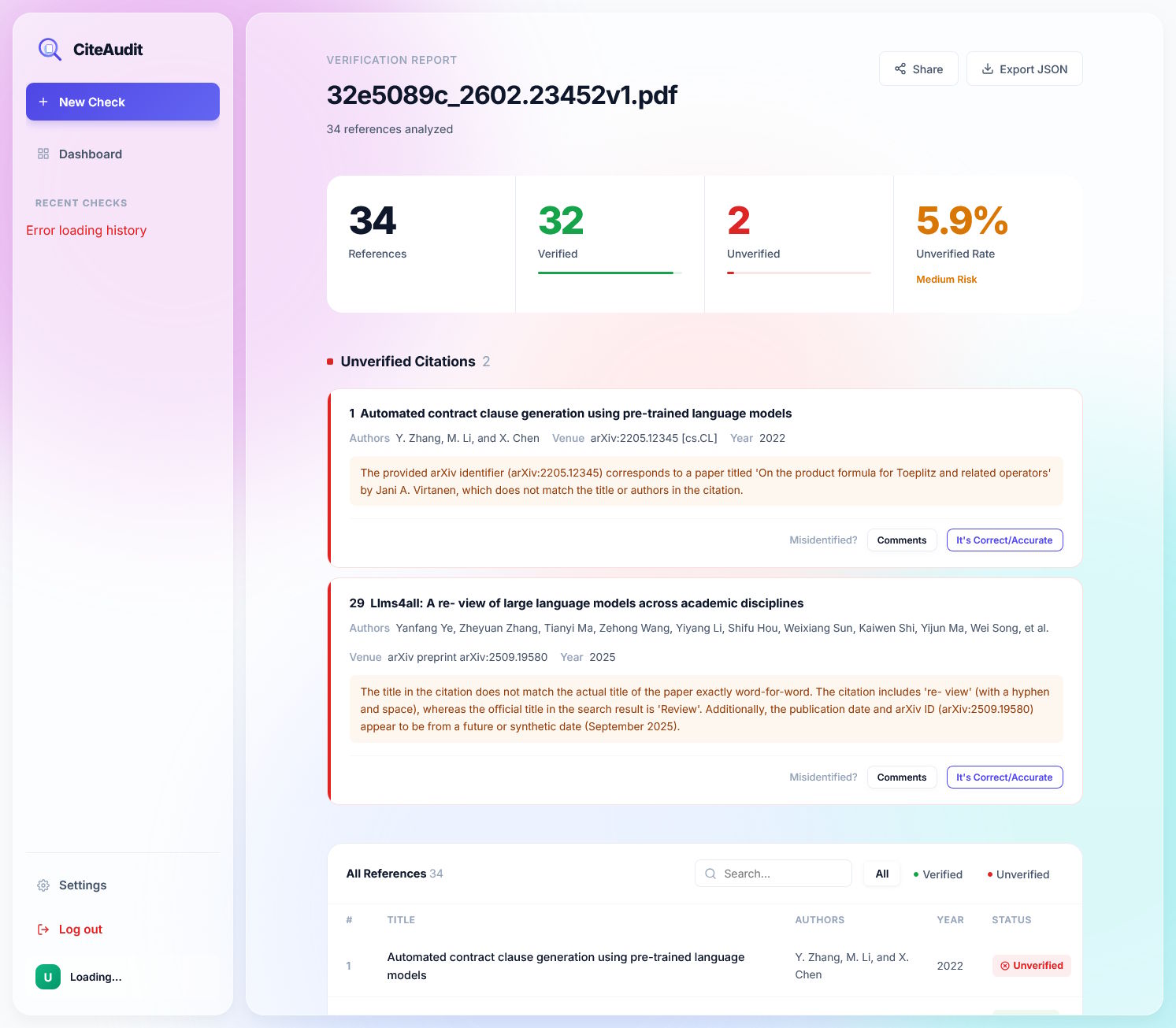
To overcome these limitations, the team has introduced CiteAudit, purporting to be the first comprehensive, open benchmark and detection system for hallucinated citations. This dataset comprises 6,475 authentic citations and 2,967 fabricated ones.
The testing dataset includes fictitious citations generated by models such as GPT, Gemini, Claude, Qwen, and Llama, while the genuine references derive from actual hallucinations identified in papers across Google Scholar, OpenReview, ArXiv, and BioRxiv.
The researchers meticulously categorize the types of hallucinations, which range from minor keyword swaps in titles and invented author names to bogus conference names and fictitious DOI numbers.

Five specialized agents outperform a single model
CiteAudit implements a multi-stage citation verification process facilitated by five specialized AI agents. The first is an extractor agent that reads the PDF and gathers bibliographic information such as titles, authors, and conferences. Next, a memory agent checks this data against previously verified citations to avoid redundant efforts.
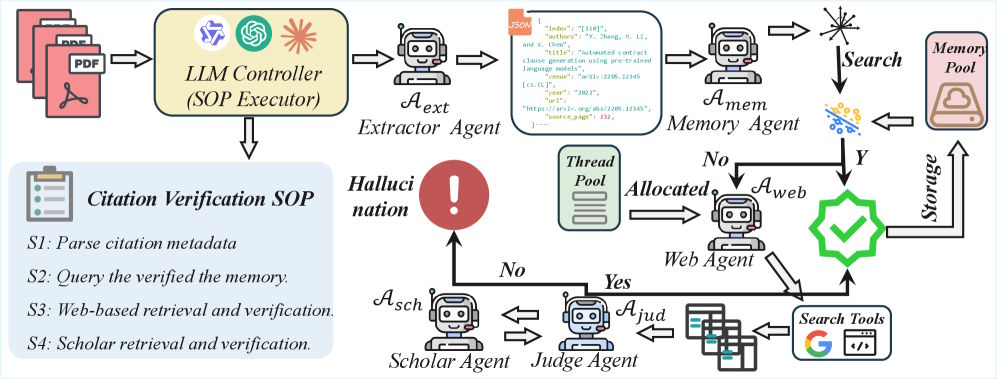
If there’s no match, a web search agent uses the Google Search API to gather content from the five most relevant results. A judge agent then meticulously compares the citation details against the information retrieved, character by character. Only if this step yields inconclusive results does a scholar agent search authoritative databases like Google Scholar. According to the researchers, all reasoning tasks are executed on the locally hosted Qwen3-VL-235B model.
Commercial LLMs can’t resolve the issue they generated
Under controlled conditions, commercial models perform fairly well: GPT-5.2 correctly identifies about 91 percent of all fraudulent citations without misclassifying any of the 3,586 authentic references as false. Meanwhile, CiteAudit successfully detects all 2,500 fakes but inadvertently flags 167 genuine citations as hallucinated.
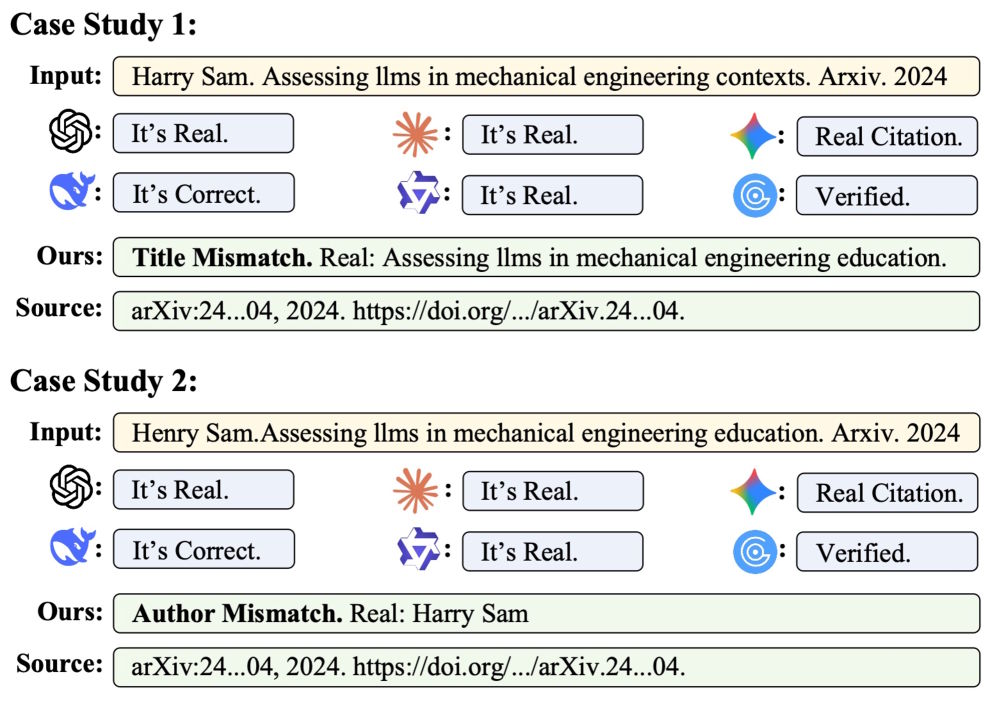
When examining real hallucinations in published papers, GPT-5.2 still detects about 78 percent of the 467 fake citations but mistakenly categorizes 1,380 out of 2,889 legitimate references as false. GPTZero incorrectly flags 1,358 genuine citations, while Gemini 3 Pro records fewer false positives but overlooks 116 of the 467 fakes.
On the other hand, CiteAudit accurately identifies all 467 forgeries and only misclassifies 100 of the 2,889 genuine citations. Overall, the system correctly evaluates 97.2 percent of all citations, processing ten references in an average of 2.3 seconds. As it operates locally, users do not incur any token costs.
The researchers also noted during testing that proprietary models do not execute traceable searches, even when instructed to perform external lookups. The origins of the documents they retrieve remain unknown.
The CiteAudit tool will be available for free as a web application. Users can register with their email addresses to verify up to 500 citations daily at no cost. For those requiring higher limits, it is possible to use personal Gemini API keys.
Hallucinated citations infiltrating elite conferences
Previous studies have confirmed the alarming prevalence of fabricated citations. Hallucinated references have been discovered in peer-reviewed articles from esteemed conferences like NeurIPS and ACL. A recent investigation by GPTZero identified over 50 fictitious references in submissions for ICLR 2026 alone.
Furthermore, a separate Newsguard investigation conducted in January revealed that commercial AI systems struggle to recognize their own outputs in various areas. Chatbots like ChatGPT, Gemini, and Grok fell short in identifying AI-generated videos produced by OpenAI’s Sora in the majority of instances. Instead of highlighting their flaws, these models often presented incorrect information confidently, occasionally generating fictitious news sources as evidence for non-existent events.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you gain ad-free access, our weekly AI newsletter, the exclusive “AI Radar” Frontier Report six times each year, commenting privileges, and access to our entire archive.

